Google Caffein Güncellemesi

Google, 8 Haziran 2010 tarihinde “Caffeine” kodadıyla gerçekleştirdiği güncellemesi ile hayatımıza farklı yenilikler girdi. Caffeine güncellemesi ile birlikte gerçek zamanlı arama sonuçlarının oluşturulmasına bir adım daha yaklaşmış oldu.

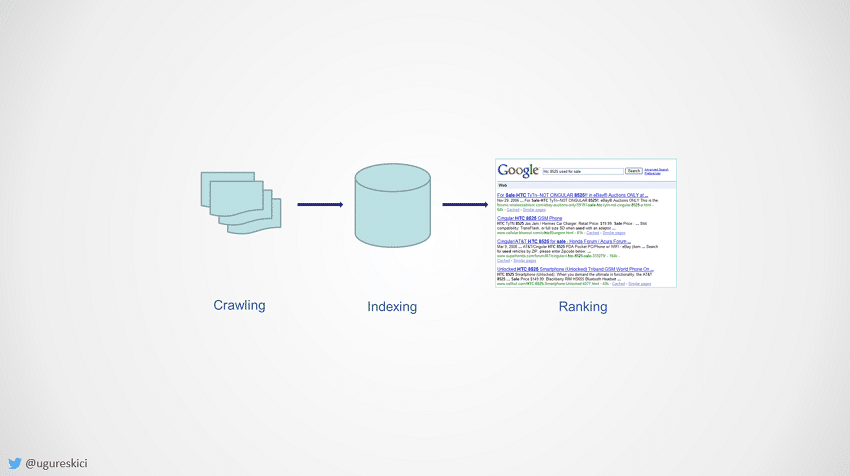
Google’ın eski indeksleme mimarisi katmanlı bir yapıya sahipti. MapReduce altyapısı ile toplanan veriler parçalanarak analiz ediliyor, sonrasında bu veri kümeleri birleştirilip anlamlı hale getiriliyor, anlamlı halen getirilen veri de arama sonuçları olarak karşımıza çıkıyordu. MapReduce dağıtık mimari üzerinde çok büyük verilerin kolay bir şekilde analiz edilebilmesini sağlayan bir sistemdir. 2004 yılında Google tarafından duyurulan bu sistem aslen 1960’lı yıllarda geliştirilen fonksiyonel programlamadaki map ve reduce fonksiyonlarından esinlenmiştir. Veriler işlenirken bu iki fonksiyon kullanılır.
Map aşamasında ana (master) düğüm (node) verileri alıp daha ufak parçalara ayırarak işçi (worker) düğümlere dağıtır. İşçi düğümler bu işleri tamamladıkça sonucunu ana düğüme geri gönderir. Reduce aşamasında ise tamamlanan işler işin mantığına göre birleştirilerek sonuç elde edilir. Daha basite indirgersek, Map aşamasında analiz edilen veri içerisinden almak istediğimiz veriler çekilir, Reduce aşamasında ise bu çektiğimiz veri üzerinde istediğimiz analiz gerçekleşir. (*)
Bu mimaride bir katmanın yenilenmesi için öncelikle botların tüm webi dolaşıp edindikleri bilgileri analiz etmek üzere veri tabanına taşımaları gerekiyordu. Herbir katmandaki data analiz edilerek veritabanı yenileniyor ve sonuçlarda gösterim işlemi gerçekleştiriliyordu. Fakat bu durum indekslenme ve verileri kullanıma hazır etme; takibinde sonuçları sunma aşamasını oldukça uzatıyordu. Bu yüzden de uzun süren indekslenme süreçleri ortaya çıkıyordu.
Eski mimarinin başlıca sorunları:
- Eski indeksleme mimarisinin birkaç katmana sahip olması
- Ana katmanın birkaç haftada bir güncellenmesi
- Bir katmanın güncellenmesi için tüm webin analiz edilmesi zorunluluğu
- Botlar yeni bir sayfa keşfettiğinde bunu arama sonuçlarına yansıtmak için üstteki sebeplerden dolayı bir gecikme & darboğaz (bottleneck) vardı
Fakat “Caffeine” güncellemesi adı altında sisteme büyük bir yenilik geldi ve “MapReduce” terk edilerek “Percolator” ismi verilen yeni bir motor (engine) aramıza katıldı.
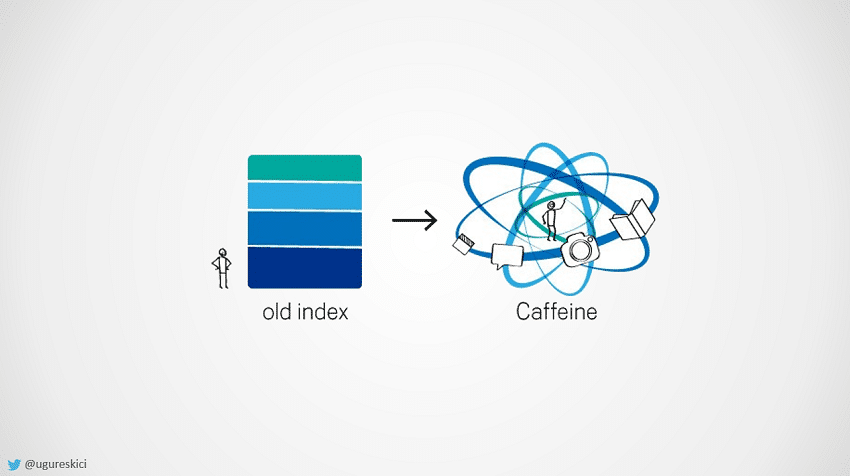
Yeni sistem, indekslenmiş olan argümanları çekmek için ortadaki darboğazı kaldırdı ve bu yeni sistemin adı “Percolator” olarak belirlendir.
Percolator, büyük bir veri kümesi içinde artan güncelleme işlemlerini işleme ve bunu Google arama indekslerine yansıtan asenkron bir sistemdir.
Yığın işleme tabanlı eski sistemin, artan işleme dayalı indeksleme sistemiyle yer değiştirilmesi sonucunda günlük aynı sayıda işlem yapılırken, Google arama sonuçlarında yer alan dokümanların ortalama yaşı %50 azaldı. Diğer bir değişle indekslerde yer alan yeni doküman sayısı %50 arttı.
*: Türkçe tanım şu adresten alıntılanmıştır: http://devveri.com/hadoop/mapreduce-nedir